

Understanding Syntax, Parsing, Semantics, and Optimization
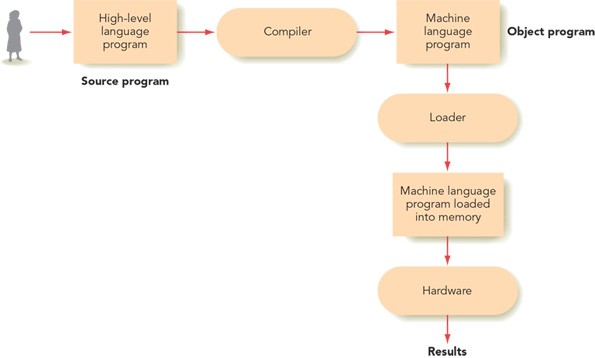
Despite the variety in high-level programming languages, no computer can directly understand them. There aren’t “Java computers” or “C++ processors”; all high-level languages must be translated into machine language for execution. This translation is done by a special piece of software called a compiler. Unlike assembly language, which translates directly into machine language, high-level languages require more complex processing. A single high-level statement often translates into multiple machine instructions.
The primary goal of a compiler is to generate machine code that accurately represents the high-level language’s instructions. It must do this without causing unintended side effects and should also aim to produce efficient and concise code. For example, a “smart” compiler should recognize opportunities to optimize code, like moving repetitive operations outside of loops.
Building a compiler is a significant challenge, involving linguistic analysis and careful translation. This chapter provides an overview of the steps involved in building a compiler for procedural languages like Java or C++. While we won’t cover every detail, you’ll gain an understanding of the key concepts and processes in compiler design and implementation.
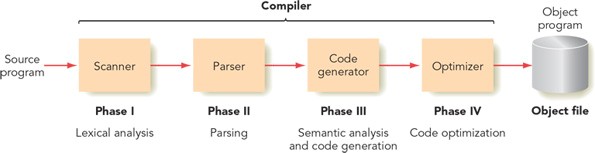
The Compilation Process
A compiler generally goes through four main phases:
- Lexical Analysis: The compiler examines the characters in the source program and groups them into tokens, which are the basic units of meaning for the language.
- Parsing: The sequence of tokens is checked for syntactical correctness based on the rules of the programming language.
- Semantic Analysis and Code Generation: If the syntax is correct, the compiler analyzes the meaning of the statements and generates the corresponding machine language instructions.
- Code Optimization: The compiler refines the generated code to make it more efficient, either by speeding it up, reducing its memory usage, or both.
Once these phases are complete, the resulting machine language code can be loaded and executed by the processor.
Phase I: Lexical Analysis
The lexical analyzer, or scanner, is responsible for grouping input characters into tokens. For example, in the statement a = b + 319 - delta;, the scanner would identify tokens like a, =, b, +, 319, -, delta, and ;. It discards unnecessary characters like spaces and tabs, then classifies each token by its type (symbol, number, operator, etc.).
Phase III: Semantics and Code Generation
Semantic analysis ensures that statements are meaningful and not just syntactically correct. For example, the statement sum = a + b; would be checked to ensure that a and b are of compatible types for addition. If everything checks out, the compiler generates the corresponding machine language code.
Phase IV: Code Optimization
Historically, code optimization was crucial because computing resources were expensive. Early compilers spent significant effort on optimizing code to make it as efficient as possible. However, with the dramatic reduction in hardware costs, optimization has become less central. Modern compilers focus more on improving programmer productivity through tools like integrated development environments (IDEs) and reusable code libraries.
Compiler design is complex and requires significant effort. While the field has evolved, the principles of translating high-level language into machine language remain a challenging and essential aspect of computer science. This chapter provided an overview of these principles, setting the stage for understanding more advanced topics in computing.
Phases of a Typical Compiler
- Lexical Analysis: Breaks down the source code into tokens, which are the smallest units of meaning, such as keywords, operators, identifiers, and symbols.
- Parsing (Syntax Analysis): Takes the tokens generated by the lexical analyzer and builds a syntax tree, checking the source code against the grammatical rules of the programming language.
- Semantic Analysis: Ensures that the syntax tree follows the language’s semantic rules, such as type checking and ensuring variables are declared before use.
- Code Generation: Translates the syntax tree into machine code or intermediate code that can be executed by the computer.
- Code Optimization: Refines the generated code to improve its efficiency, typically by reducing memory usage or speeding up execution.
Demonstrate How to Break Up a String of Text into Tokens
Given a string of code, for example, int sum = a + b;, the lexical analyzer would produce the following tokens:
int(keyword)sum(identifier)=(assignment operator)a(identifier)+(addition operator)b(identifier);(semicolon)
Understand Grammar Rules Written in BNF and Use Them to Parse Statements
Backus-Naur Form (BNF) is a notation for expressing the grammar of a language. For example:
- Grammar Rule:
<assignment> ::= <identifier> = <expression> ; - Parsing Example: For the statement
sum = a + b;, BNF would break it down as: <assignment>→sum = a + b;<identifier>→sum<expression>→a + b- Further broken down as
<term> + <term>where each<term>is an identifier (aandb).
Explain How Semantic Analysis Uses Semantic Records to Determine Meaning
Semantic analysis checks the correctness of operations within the context of the language’s rules. For instance, it ensures that an operation like a + b makes sense by checking the types of a and b. Semantic records store information about each identifier, such as its type and scope. If a is an integer and b is a string, the semantic analyzer would flag an error because adding an integer to a string is not meaningful in most languages.
Show What a Code Generator Does
The code generator converts the syntax tree into machine code. For example, for the statement sum = a + b;, it might produce assembly language instructions like:
LOAD aADD bSTORE sum
This machine code is what the CPU can execute directly.
Explain the Historical Importance of Code Optimization, and Why It Is Less Central Today
In the early days of computing, hardware was expensive, and resources were limited, so it was crucial for compilers to produce highly optimized code to make the best use of these resources. As hardware became cheaper and more powerful, the emphasis shifted from optimization to improving programmer productivity through tools and environments that make coding easier, even if the resulting code is not perfectly optimized.
Example of Local and Global Code Optimization
- Local Optimization: Within a small block of code, replacing a slow operation with a faster one. For example, replacing a multiplication by 2 with an addition (
x * 2becomesx + x). - Global Optimization: Across larger sections of code, such as moving a constant calculation out of a loop to prevent it from being recalculated on every iteration. For example:
// Before Optimization
for (int i = 0; i < 1000; i++) {
result[i] = x * 2;
}
// After Global Optimization
int temp = x * 2;
for (int i = 0; i < 1000; i++) {
result[i] = temp;
}This reduces the multiplication operation from 1000 times to just once.
Syntax, Grammars, Parsing, Semantics, and Optimization
These foundational topics in compiler design are crucial to understanding how high-level code is transformed into machine code. Each topic involves a deep and complex set of theories and practices:
- Syntax refers to the structure or form of the code, governed by rules that dictate how symbols can be combined to form valid programs. Syntax analysis ensures that the code follows the grammatical rules of the programming language.
- Grammars are formal descriptions of the syntax of a programming language, typically expressed in notations like Backus-Naur Form (BNF). Grammars are used to define the structure of valid sentences or statements in a language.
- Parsing is the process of analyzing a sequence of tokens to determine its grammatical structure according to a given grammar. Parsers construct syntax trees or abstract syntax trees (ASTs) that represent the hierarchical structure of the code.
- Semantics refers to the meaning of the code. Semantic analysis goes beyond syntax to ensure that the operations in the code make sense (e.g., adding two numbers, calling a method on an object). It involves checking types, scopes, and other contextual rules.
- Optimization is the process of improving the generated code to make it more efficient. This can involve reducing memory usage, speeding up execution, or other performance enhancements. Optimization can be local (within small blocks of code) or global (across larger segments or entire programs).

Integrated Development Environments (IDEs) and Support Tools
IDEs are comprehensive software suites that provide tools to make software development easier and more efficient. They typically include:
- Code Editors: Text editors with features like syntax highlighting, auto-completion, and error detection.
- Compilers/Interpreters: Tools to compile or interpret the code directly from the IDE.
- Debuggers: Tools that allow developers to step through code, set breakpoints, and inspect variables.
- Version Control Integration: Integration with systems like Git to manage code versions and collaboration.
- Build Automation Tools: Tools that automate the process of compiling code, running tests, and packaging software.
- Profilers: Tools to analyze the performance of the code, such as memory usage and execution time.
IDEs are crucial for modern development because they bring all these tools together in one place, improving developer productivity and reducing the complexity of managing different tools.
Compilers for Alternative Languages
Compilers are not limited to traditional imperative languages like C or Java. There are compilers for:
- Functional Languages: Such as Haskell or Lisp, where the focus is on function application and recursion rather than state changes.
- Object-Oriented Languages: Such as Java or C++, where the focus is on objects and their interactions.
- Parallel Languages: Such as OpenMP or CUDA, designed for parallel processing, where the focus is on dividing tasks among multiple processors or cores.
Each of these types of languages presents unique challenges for compiler design. For example, functional languages often require advanced optimizations for recursion and lazy evaluation, while parallel languages need to manage synchronization and data distribution across multiple threads or processors.
Language Standardization
Language standardization ensures that a programming language is consistently implemented across different platforms and compilers. This involves:
- Defining a Formal Specification: A detailed document that describes the syntax, semantics, and features of the language.
- Ensuring Compatibility: Compilers must adhere to the standard so that code written in the language behaves consistently, regardless of the compiler or platform.
- Supporting Interoperability: Standardization also allows code written in different languages to interact seamlessly, using common standards like the C ABI (Application Binary Interface).
Standardization is critical for widespread adoption of a language, as it ensures that developers can rely on consistent behavior across different environments.

Top-Down versus Bottom-Up Parsing Algorithms
Parsing algorithms can be broadly categorized into top-down and bottom-up approaches:
- Top-Down Parsing: Starts from the highest-level rule (the start symbol) and works downwards, attempting to match the input tokens with the rules of the grammar. An example is the recursive descent parser, which uses recursive procedures to process the input.
- Advantages: Simpler to implement for certain types of grammars, and more intuitive.
- Disadvantages: May struggle with left-recursive grammars and is generally less powerful than bottom-up parsing.
- Bottom-Up Parsing: Starts from the input tokens and works upwards, building the parse tree by finding sequences of tokens that match the rules of the grammar. LR parsers (Left-to-right, Rightmost derivation) are a common type of bottom-up parser.
- Advantages: More powerful and can handle a broader range of grammars, including left-recursive grammars.
- Disadvantages: More complex to implement and understand.
Choosing the right parsing algorithm depends on the language’s grammar and the specific requirements of the compiler.
Error Detection and Recovery
Handling errors is a critical part of compiler design. There are two main aspects:
- Error Detection: The compiler must identify syntax errors (e.g., missing semicolons, unmatched braces) and semantic errors (e.g., type mismatches, undeclared variables). This is typically done during the parsing and semantic analysis phases.
- Error Recovery: After detecting an error, the compiler must decide how to proceed. There are several strategies:
- Panic Mode: Skips input tokens until a likely recovery point (e.g., the end of a statement) is found.
- Phrase-Level Recovery: Attempts to correct the error by inserting, deleting, or altering tokens.
- Error Productions: Extends the grammar with additional rules that describe common errors, allowing the parser to continue with a modified input.
- Global Correction: Tries to find the minimal set of changes needed to make the input syntactically correct.
Effective error detection and recovery are essential for creating a user-friendly compiler that can help developers quickly identify and fix issues in their code.
These topics highlight the complexity and depth of compiler design. Each area requires careful consideration and sophisticated algorithms to create a robust and efficient compiler. While this overview touches on the key concepts, entire books could be written on each topic, reflecting their importance and intricacy in the field of computer science.



+ There are no comments
Add yours